When Your System Detects Failure Before You Even Log In: The Rise of AI-Driven Incident Response
Introduction — From Panic to Precision:
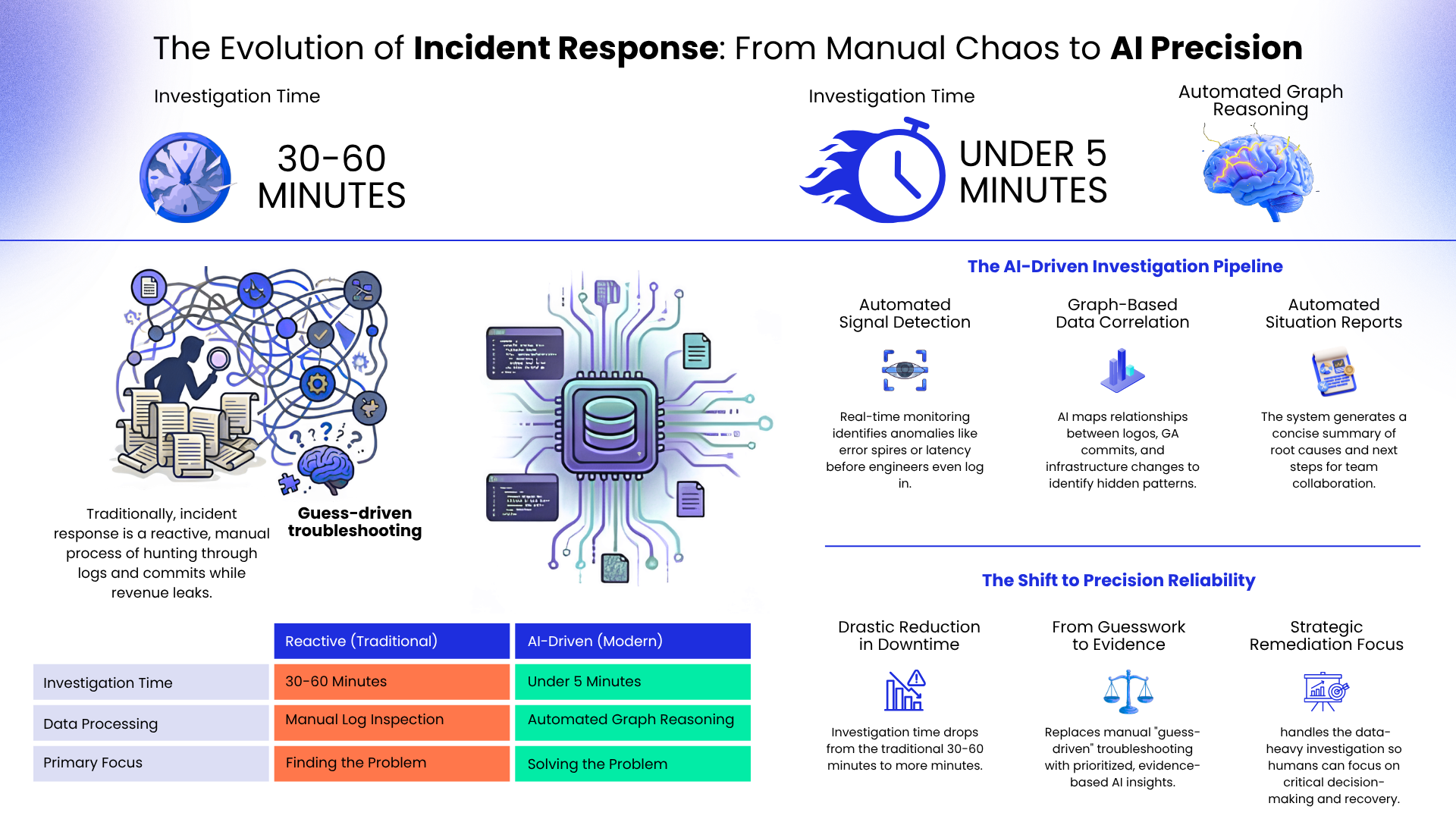
A payment gateway goes down at 3 PM on a busy weekday. Transactions halt instantly; revenue leaks every minute, and engineering teams rush to dashboards trying to understand what happened. Traditionally, this moment triggers chaos — logs everywhere, alerts firing, and multiple hypotheses competing for attention.
But what if the system already knew the cause before engineers even logged in?
AI-driven incident response is changing how organizations handle outages. By combining observability data, automated reasoning, and intelligent workflows, modern systems can investigate failures, correlate signals, and generate actionable insights within minutes — not hours.
The Turning Point: From Reactive Troubleshooting to Early Diagnosis:
Historically, incident response has been reactive:
- Engineers manually inspect cloud logs.
- Teams review recent Git commits.
- Infrastructure changes are analyzed after problems escalate.
This process can easily take 30–60 minutes, creating financial risk and operational instability.
Today, monitoring alerts from platforms like Google Cloud Operations Suite can trigger an intelligent investigation pipeline. Instead of simply notifying humans, AI agents analyze patterns across logs, infrastructure events, and deployment history to detect correlations automatically.
The result is a shift from guess-driven troubleshooting to evidence-based diagnosis.
Key Concepts Explained Simply:
AI-Driven Incident Response
An automated workflow where AI systems analyze monitoring signals, logs, and changes in real time to identify probable root causes.
Graph-Based Reasoning
Instead of reading logs sequentially, systems map relationships between services, deployments, and infrastructure into a connected structure. This allows AI to ask contextual questions like:
- Which deployment preceded by the latency spike?
- Did an infrastructure update occur before the error rate increase?
Automated Situation Reports
AI summarizes technical findings into structured reports shared through collaboration platforms like Slack or Microsoft Teams, enabling faster team alignment.
Technical Deep Dive: How the Pipeline Works:
1. Trigger — Detecting the Signal
Real-time monitoring tools detect anomalies such as:
- Error spikes
- Latency increases
- Service degradation
These signals initiate an automated investigation rather than just raising alerts.
2. Investigation — Data Integration
The system pulls information from multiple sources:
- Application and infrastructure logs
- Production branches commit history
- Infrastructure-as-Code changes (e.g., Terraform)
Graph orchestration frameworks structure this data into a connected knowledge model, enabling semantic reasoning.
3. Diagnosis — Machine Learning Analysis
AI models analyze dependencies and timelines to form hypotheses. For example:
- An authorization of API failure begins two minutes after a merged pull request deploys.
- Latency spikes correlate with a recent infrastructure configuration change.
Instead of raw data, engineers receive prioritized insights.
4. Reporting — Automated Collaboration
The system generates a concise “Situation Report” that includes:
- Suspected root cause
- Timeline of events
- Impacted services
- Recommended next actions
This report is automatically shared with operational teams.
Practical Use Cases: Tech and Non-Tech Perspectives:
For Technical Teams
- Faster root cause analysis
- Reduced alert fatigue
- Better correlation across distributed systems
For Business and Operations Leaders
- Minimized downtime costs
- Improved customer experience
- Stronger service reliability and compliance posture
Step-by-Step Example Workflow:
- Monitoring detects abnormal error rates.
- AI agent pulls logs, commits, and infrastructure updates.
- Graph reasoning maps relationships between events.
- ML models identify likely cause-effect patterns.
- The situation report is generated and sent to collaboration tools.
- Engineers focus on remediation instead of investigation.
Best Practices for Implementing AI Incident Response
- Centralize observability data across services.
- Maintain structured metadata for deployments and commits.
- Use graph-based orchestration to unify data silos.
- Continuously train models on past incident patterns.
- Integrate automated summaries into team workflows.
Common Mistakes and Misconceptions
- Mistake: Assuming AI replaces engineers.
Reality: AI accelerates investigation; human expertise remains essential for decision-making.
- Mistake: Treating monitoring tools and AI pipelines as separate systems.
Reality: Deep integration is necessary for accurate insights.
- Mistake: Ignoring data governance and access control.
Reality: Enterprise environments require strict permission boundaries.
Future Scope: The Evolution of Intelligent Operations:
As AI systems mature, incident responses will become increasingly proactive. Instead of reacting to outages, models will predict risk patterns before failures occur. Graph-based reasoning combined with adaptive machine learning will enable systems to simulate deployment impacts and recommend preventive actions automatically.
This evolution moves reliability engineering toward continuous intelligence, where insights flow constantly rather than only during crises.
Conclusion — A New Mindset for Reliability Engineering:
AI-driven incident response is not just automation — it represents a fundamental shift in how organizations think about uptime and resilience. By connecting observability data, graph reasoning, and machine learning, modern platforms transform outages from chaotic emergencies into structured, solvable events.
Key Takeaways:
- AI can correlate logs, commits, and infrastructure changes in real time.
- Graph-based reasoning enables deeper contextual analysis.
- Automated reports reduce noise and accelerate decision-making.
- Engineers shift from manual investigation to strategic remediation.
- Faster incident response directly protects revenue and customer trust.
When infrastructure runs smoothly, it’s often these invisible AI systems working quietly in the background — analyzing millions of signals and ensuring businesses keep moving forward.
Related Blogs

Transforming Paper Chaos into Digital Clarity: How AI Agents Turn Legacy Blueprints into ERP-Ready Data
